
Поговорим сегодня о Proxmox! Промышленное решение для организации ИТ-инфраструктуры компании под свободной лицензией (платна только подписка на обновления и поддержку). Proxmox VE 3.X являет собою дистрибутив на основе Debian, со специально пропатченным ядром на базе 2.6 для OpenVZ. После настройки нодов в составе кластера, все управление производится через веб-интерфейс. Proxmox — промышленное решения уровня VMware.
*запись дополнена 3.04.2015
Когда дело доходит до промышленного решения, то необходимо выбирать максимально простое, понятное и монолитное решение… которое проверенно временем. Тут уже нет места экспериментальным технологиям. И, что особенно важно, всегда играет не малую роль и человеческий фактор — т.е. систему нужно поставить и научить людей ею правильно пользоваться (в нашем случае, админов). И здесь очень важно, чтобы был нормальный интерфейс для управления этими делами, т.к. многие работать с «голой» командной строкой просто откажутся или не смогут. Также важны очень многие встроенные функции, такие как: отсутствие централизованного узла (состояние кворума), объединение серверов в кластер и все сопутствующие этому фишки.
В моем случае, использоваться будут в основном контейнеры OpenVZ, но обычно виртуалки KVM являются более востребованной функцией, нежели контейнеры (для них мы и будем стараться по ходу статьи). Но и про контейнеры хотелось бы замолвить словечко… Я бы с удовольствием использовал LXC, вместо OpenVZ (которые является ему, по сути — отцом), но для LXC до сих пор отсутствует внятный веб-интерфейс (форкам LXC Web Panel на github я бы дал статус — experimental), а про объединение в кластер и речи не идет… а когда нам нужно автоматизировать целый дата-центр, как быть без этого? В чем же разница между OpenVZ и LXC? Хм, да по большому счету это одно и тоже, если не вдаваться в код. По сути, разница лишь в том, что OpenVZ использует свое пропатченное ядро 2.6 (со включенными всеми патчами по безопасности, свежим KVM и дровами), а LXC включен в апстрип, т.е. в ванильное ядро начиная с 3.8. И как бы со временем, очевидно что он будет еще сильнее допилен, и «выдавит» OpenVZ. Но на данный момент, OpenVZ в составе Proxmox выглядит более готовым и завершенным решением (разработчики Proxmox обещают в будущих релизах заменить OpenVZ на LXC.. когда они будут равносильны по функциональности).
Кстати… удивительно, но насчет Proxmox в рунете я практически не нашел никакой документации на русском языке. Все только на буружуйских офф.доках и форумах. Так что, этот мануал должен быть довольно полезен для общественности :)
Ладно, хватит демагогии.. поехали устанавливать и настраивать наш дистр на ноды!
1) Установка
Система устанавливается очень просто. Одно требование — железный рейд (софтверные и гибридные не поддерживаются). Драйвера определяются автоматически (все вшито в ядро). Про установке, вас попросят указать IP, пароль и имя машины. Затруднений тут возникнуть не должно. Один момент, на который стоит обратить внимание — это FQDN-имя. Я рекомендую указывать в таком формате: имя.local, например: node1.local и ничего тут не мудрить с доменами. После завершения установки, можно заходить на веб-интерфейс по адресу: https://SERVER-IP:8006
Практика показывает: разные кластера должны быть в разных подсетях, чтобы не мешать друг другу (пример: один кластер в 1.1.1.X, второй в 1.1.2.X, маска и шлюз везде одинаковы).
2) Настройка нод
После установки, дайте на этот адрес интернет и обновите систему. При обновлении, система будет ругаться на ошибки при доступе к репозиториям Proxmox. Это нормально, доступ к обновлениям платный. Но это не страшно, нам же нужно обновить только дебиановские свободные пакеты.
apt-get update apt-get upgrade
После обновления, проверьте дату и время на соответствие с реальным положением дел.
date
Если время не соответствует, поправьте его (опционально):
date --set hh:mm
или
date MMDDhhmmYYYY.ss
где:
MM — месяц
DD — день
hh — час
mm — минуты
YYYY — год
ss — секунды
После этого, настройка ноды считается законченной. Настройте все остальные ноды и только потом объединяйте их в кластер.
3) Создание кластера, добавление нод в кластер
Сначала, на первой ноде нужно создать кластер. Это делается единоразово.
3.1) Создание кластера
Здесь же можно задать имя кластера (в дальнейшем изменить его будет нельзя):
pvecm create YOUR-CLUSTER-NAME
Проверить статус кластера:
pvecm status
Все! Дальше нужно только добавлять в него уже настроенные ноды.
3.2) Добавление нод в кластер
Чтобы добавить ноды в кластер, выполните команду (выполнять команды нужно на самой добавляемой ноде):
pvecm add IP-ADDRESS-CLUSTER
где IP-ADDRESS-CLUSTER — адрес уже добавленной ноды (рекомендую указывать самую первую).
При добавлении вас попросят принять RSA-ключ (нужно будет ввести «yes» когда спросят) и ввести пароль от рута той ноды, с которой мы соединяемся.
Проверить статус кластера:
pvecm status pvecm nodes
Все! Офф. доки на эту тему: https://pve.proxmox.com/wiki/Proxmox_VE_2.0_Cluster#Create_the_Cluster
Практика показывает: все ноды кластера лучше прописать всем серверам кластера в /etc/hosts для надежности.
3.3) Удаление ноды из кластера
Этот пункт требует особого внимания, если тут накосячить — можно сломать весь кластер. Значит так, сначала нужно убрать все ВМ с удаляемой ноды (перенести их на другой сервера или удалить вовсе). После, нужно выключить эту ноду и физически отключить ее из сети (важно: убедитесь, что в текущем ее состоянии она больше никогда не появится в сети!)
Проверить количество нод:
pvecm nodes
Удалить ноду:
pvecm delnode IP-ADDRESS-NODE
Что удалит ноду из кластера. Все, больше доп. действий не требуется.
Проверить количество нод еще раз:
pvecm nodes
Если потом эту ноду нужно будет вернуть в кластер, то на ней нужно полностью под чистую переустановить Proxmox + дать ей новое имя и новый IP = ввести ее в кластер как новую (см. пункт 3.2).
4) Подключение хранилища
Ноды настроены и готовы, объединены в кластер…. самое время подключить хранилище. Здесь мы рассмотрим типичный пример используемый нами, подключения хранилища к серверам напрямую через Fibre Channel. Основная настройка, конечно же, происходит с самим хранилищем. В нашем случае это будет IBM Chassis C4A (на 24 SAS диска IBM, 22 из которых объединены в RAID6). Его нужно настроить «как обычно» (это тема для отдельной статьи). После подключить его к уже готовым нодам. Особенность работы с хранилищем, подключенного через LVM: на нем можно разместить только диски виртуалок KVM (и только в формате raw), но никак не файлы контейнеров OpenVZ.
Проверить устройства:
ls -l /dev/sd*
Ответ должен быть приблизительно таким:
root@node1:~# ls -l /dev/sd* brw-rw---T 1 root disk 8, 0 Feb 3 21:26 /dev/sda brw-rw---T 1 root disk 8, 1 Feb 3 21:26 /dev/sda1 brw-rw---T 1 root disk 8, 2 Feb 3 21:26 /dev/sda2 brw-rw---T 1 root disk 8, 3 Feb 3 21:26 /dev/sda3
В условиях с одним родным рейдом, должны быть только диска sda1,2,3… Перезагружаем наши сервера по очереди. Когда на всех серверах объявится новое устройство sdb, можно приступать к диагностике.. либо сразу к подключению хранилища. Внешнее хранилище, подключенное через LVM может использовать только raw формат дисков для VM.
4.1) Диагностика (опционально)
Опишем, как стоит проводить диагностику того, что хранилище «зацепилось» и система его видит. Это действие не является обязательным, а в случае выполнения — его достаточно проделать только на одной ноде.
Проверить устройства:
ls -l /dev/sd*
Ответ должен быть приблизительно таким:
root@node2:~# ls -l /dev/sd* brw-rw---T 1 root disk 8, 0 Feb 3 21:22 /dev/sda brw-rw---T 1 root disk 8, 1 Feb 3 21:22 /dev/sda1 brw-rw---T 1 root disk 8, 2 Feb 3 21:22 /dev/sda2 brw-rw---T 1 root disk 8, 3 Feb 3 21:22 /dev/sda3 brw-rw---T 1 root disk 8, 16 Feb 4 10:56 /dev/sdb
После перезагрузки, там должно появится это самое устройство sdb. Это и есть наше хранилище. Хотите убедится в этом на 100%? Ок, поехали!
Проверям, что система видит контроллер Fibre Channel и дрова на него встали.
lspci -vmm | grep Fibre
Ответ должен быть приблизительно таким:
root@node1:~# lspci -vmm | grep Fibre Class: Fibre Channel Device: Saturn: LightPulse Fibre Channel Host Adapter SDevice: Saturn: LightPulse Fibre Channel Host Adapter
Это хорошо. Далее, установим необходимые нам тулзы для диагностики:
apt-get install scsitools lsscsi
Сканируем на поиск новых устройств:
rescan-scsi-bus
Ответ должен быть приблизительно таким:
root@node1:~# rescan-scsi-bus ... Scanning for device 2 0 0 0 ... OLD: Host: scsi2 Channel: 00 Id: 00 Lun: 00 Vendor: IBM Model: 1746 FAStT Rev: 1070 Type: Direct-Access ANSI SCSI revision: 05 Scanning for device 2 0 0 31 ... OLD: Host: scsi2 Channel: 00 Id: 00 Lun: 31 Vendor: IBM Model: Universal Xport Rev: 1070 Type: Direct-Access ANSI SCSI revision: 05 ...
А теперь мы убеждаемся, что наше хранилище соответствует именно букве sdb:
lsscsi
Ответ должен быть приблизительно таким:
root@node1:~# lsscsi [0:2:0:0] disk LSI RAID SAS 6G 0/1 2.13 /dev/sda [1:0:0:0] cd/dvd HL-DT-ST DVDRAM GT80N SF03 /dev/sr0 [2:0:0:0] disk IBM 1746 FAStT 1070 /dev/sdb [2:0:0:31] disk IBM Universal Xport 1070 -
Проверяем еще раз и убеждаемся, что все на месте.
ls -l /dev/sd*
На этом диагностика завершена. Можно приступать к созданию LVM и подключению его к Proxmox VE.
4.2) Создание LVM
LVM — особая технология хранения в Linux, благодаря которой мы сможем обеспечить живую миграцию машин с ноды на ноду. Итого, все это работает подобно VMware vMotion. Ее настройка очень проста :) Все пункты делаются только один раз, при первичном подключении хранилища в кластеру.
Обозначаем том sdb как устройство LVM (особое внимание: опасность потери данных на sdb! Вы должны четко понимать, что делаете…):
pvcreate /dev/sdb
Создаем на устройстве sdb группу, под названием «ibm»:
vgcreate ibm /dev/sdb
Все! Все настройки автоматически синхронизируются со всем кластером. Далее, просто заходим в веб-интерфейс и «пристегиваем» наш LVM.
Datacenter >>> Storage >>> Add >> LVM в графе «Volume Group» выбираем ibm.
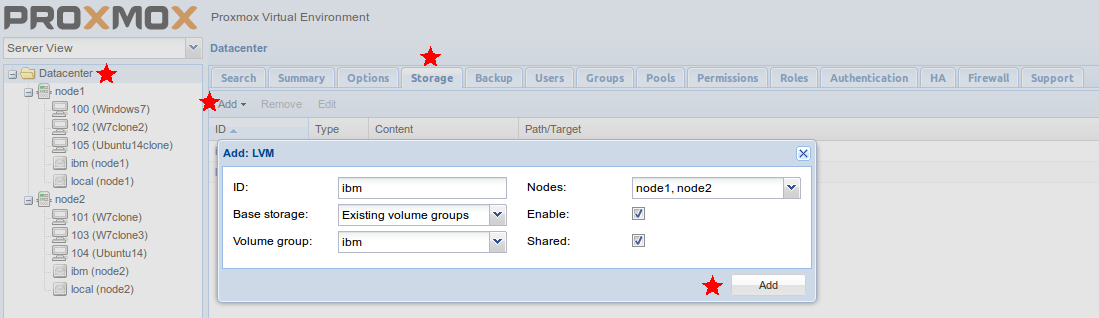 Все! Хранилище успешно добавлено и актуализировалось на всех обозначенных вами нодах.
Все! Хранилище успешно добавлено и актуализировалось на всех обозначенных вами нодах.
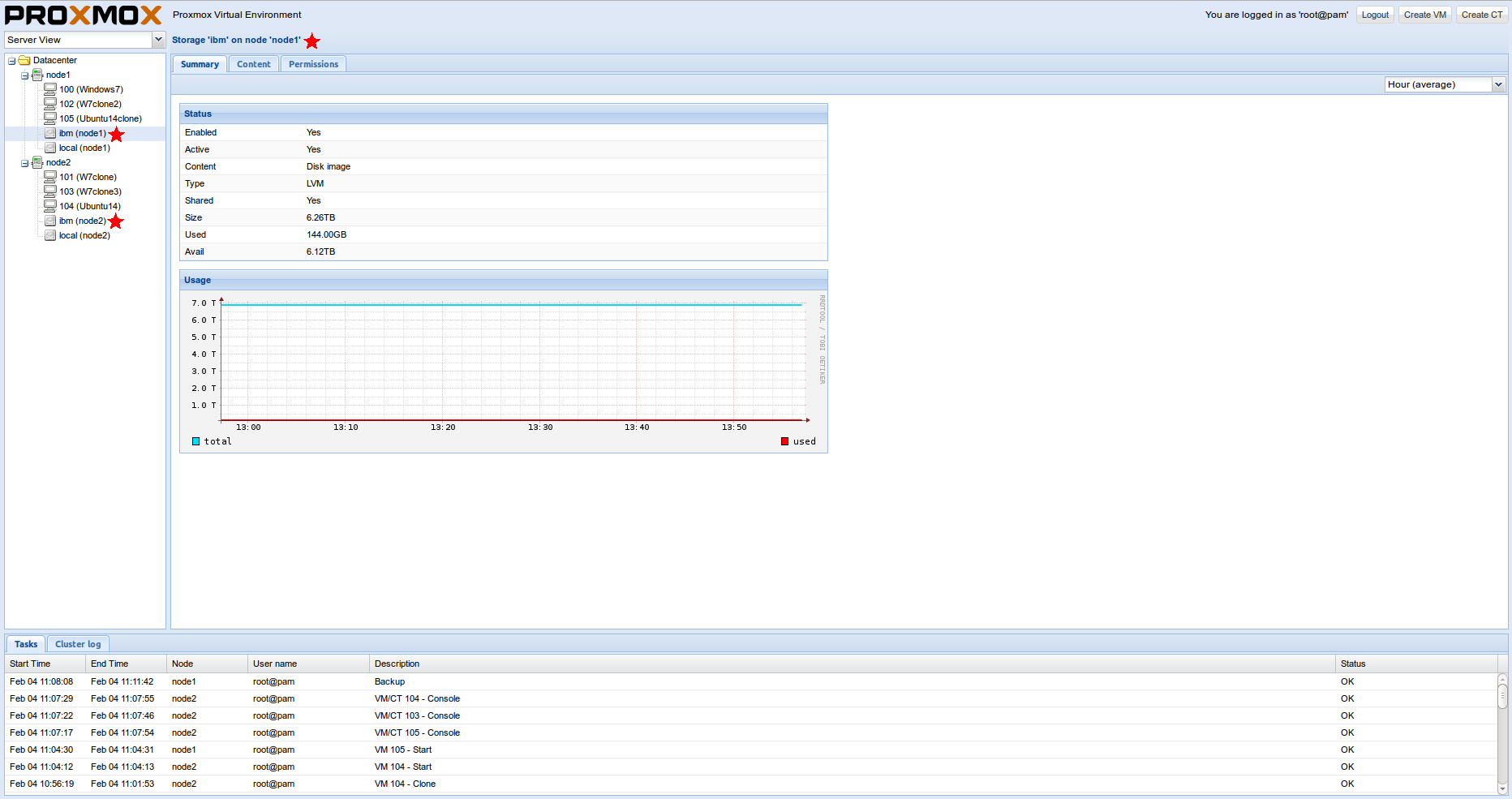 Офф. доки на эту тему: http://pve.proxmox.com/wiki/Storage_Model
Офф. доки на эту тему: http://pve.proxmox.com/wiki/Storage_Model
5) Multipath
Multipath — технология подключения узлов сети хранения данных с использованием нескольких маршрутов. В нашей конфигурации используется 2 FC контроллера со стороны сервера + 2 FC контроллера со стороны сервера хранилища + SAN-свитч. Итого выходит, что хранилище видно по 4-м каналам. Подключение хранилища через multipath обеспечивает агрегацию каналов и их резервирование, на уровне ядра системы. Это увеличивает скорость, а в случае отказов — незаметно для пользователя использует доп. каналы. Чтобы вы понимали, сама технология является частью ядра Linux, и в большинстве случаев (на нормальном железе) вся конфигурация определяется автоматически. Итак, установим тулзы:
apt-get install multipath-tools
Проведите диагностику, как это показано в п.4.1. Проверить id каждого диска можно командой:
/lib/udev/scsi_id -g -u -d /dev/sdc
В нашем случае конфиг определился автоматически. Общая картина у нас такая (при подключении только одного хранилища к SAN-свичу):
root@node3:~# ls -l /dev/sd* brw-rw---T 1 root disk 8, 0 Mar 25 14:50 /dev/sda brw-rw---T 1 root disk 8, 1 Mar 25 14:50 /dev/sda1 brw-rw---T 1 root disk 8, 2 Mar 25 14:50 /dev/sda2 brw-rw---T 1 root disk 8, 3 Mar 25 14:50 /dev/sda3 brw-rw---T 1 root disk 8, 16 Mar 25 14:50 /dev/sdb brw-rw---T 1 root disk 8, 32 Mar 25 14:50 /dev/sdc brw-rw---T 1 root disk 8, 48 Mar 25 14:50 /dev/sdd brw-rw---T 1 root disk 8, 64 Mar 25 14:50 /dev/sde
sdb, sdc, sdd, sde — наше хранилище и его 4-ре канала.
Проверяем, автоопределился ли multipath:
multipath -ll
root@node3:~# multipath -ll 360080e50003e2c4c000003b555000a25 dm-2 IBM,1746 FAStT size=11T features='3 queue_if_no_path pg_init_retries 50' hwhandler='1 rdac' wp=rw `-+- policy='round-robin 0' prio=1 status=active |- 7:0:1:0 sdc 8:32 active ready running |- 7:0:2:0 sdd 8:48 active ready running |- 8:0:0:0 sdf 8:80 active ready running `- 8:0:1:0 sdg 8:96 active ready running
Более полная информация выводится командой:
multipath -v3
Как мы видим, хранилище подключено 4-мя каналами. Но ключевым параметром тут является id: 360080e50003e2c4c000003b555000a25, а дополнительным: dm-2 (это временное имя хранилища). Так вот, монтируется в систему оно потом в любом случае по id автоматически, а имя нам потребуется для создания LVM в п.4.2.
На это имя мы и создаем LVM:
pvcreate /dev/dm-2 vgcreate ibm /dev/dm-2
Все! Дальше, хранилище осталось активировать через веб-интерфейс, как уже было показано выше.
Офф. доки на эту тему: http://pve.proxmox.com/wiki/ISCSI_Multipath
6) High Availability service (HA)
Это, пожалуй, самая сложная часть. По-умолчанию VM работают в классическом режиме: размещены на сервере, но если сервер становится недоступен, то все VM становятся недоступны вместе с ним. В режиме же HA, происходит следующее: в случае отказа сервера, все его VM автоматически переезжают на другой сервер(а) кластера. HA настраивается просто, через веб-GUI. Однако, одним из требований работы HA (в добавок к high-end оборудованию и совместному хранилищу) является наличие аппаратного Fencing-устройства для каждого сервера (чтобы избежать одновременного ошибочного доступа к данным VM с нескольких серверов, это называется «split-brain condition» и может привезти к «data corruption»). Именно этим и важен Fencing, он выполняет роль вышибалы — физически блокирует доступ сервера к данным VM (закрывает SAN порты, отключает от сети или от питания, либо просто перезагружает сервер). Аппаратный Fencing — является наиболее эффективным и стабильным решением. Примеры таких устройств: APC реки, SAN свитчи.. и сервисы на подобии HP iLO. В нашем случае, мы будем использовать утилиту HP ILO, которая вшита в наши сервера HP DL360 Gen9. Она идеально подходит для данной роли. Подключите и настройте iLO на сервере, задайте ему пароль и настройте доступ. После, продолжаем:
6.1) Fencing
Настройка происходит полностью через консоль и конфиги. Морально приготовьтесь. Более того, под каждое Fencing-оборудование будут свои, особые конфиги. Перво-наперво, надо активировать программный Fencing-домен и объединить в него все сервера кластера (данные операции выполнить на всех серверах). Для это нужно раскоментить строку (FENCE_JOIN=»yes») в этом конфиге:
nano /etc/default/redhat-cluster-pve
Перезапустим сервис:
/etc/init.d/cman restart
Проверяем и добавляем сервер в Fencing-домен:
fence_tool join fence_tool ls
После этого у сервера может произойти потеря синхронизации с кластером. Необходимо теперь перезапустить главный сервис:
service pve-cluster restart
Далее, устанавливаем тулзы для связи с HP iLO из ОС с помощью интерфейса IPMI:
apt-get install ipmitool openipmi
Запуск и перезапуск сервиса:
invoke-rc.d ipmievd start invoke-rc.d ipmievd restart
Очевидно, что он будет ругатся… для работы IPMI необходимо активировать доп.модули ядра системы:
modprobe ipmi_devintf modprobe ipmi_si
Сделаем так, чтобы они активировались автоматически после ребута ОС (поправить конфиг и вставить туда след.значения):
nano /etc/modules ipmi_devintf ipmi_si
Проверяем теперь:
cat /proc/devices ipmitool -I open chassis status
В 1-м случае должен появится девайс ipmidev, а во втором выхлоп будет похож на это:
root@node1:~# ipmitool -I open chassis status System Power : on Power Overload : false Power Interlock : inactive Main Power Fault : false Power Control Fault : false Power Restore Policy : always-on Last Power Event : Chassis Intrusion : inactive Front-Panel Lockout : inactive Drive Fault : false Cooling/Fan Fault : false Front Panel Control : none
Проверяем Fencing. Эти команды делают приблизительно одно и тоже (1-2 проверяют статус, 3 — отправляет в ребут… логин и пароль от iLO):
ipmitool -I lanplus -H 172.16.1.211 -U Administrator -P Password power status fence_ilo4 -P -C 1 -a 172.16.1.211 -l Administrator -p Password -o status fence_ilo4 -P -C 1 -a 172.16.1.211 -l Administrator -p Password -o reboot
Чтобы не палить пароль в конфиге напрямую (в т.ч. веб-GUI), напишем простейший скрипт:
nano /root/ilo #!/bin/bash echo "Password" chmod +x /root/ilo
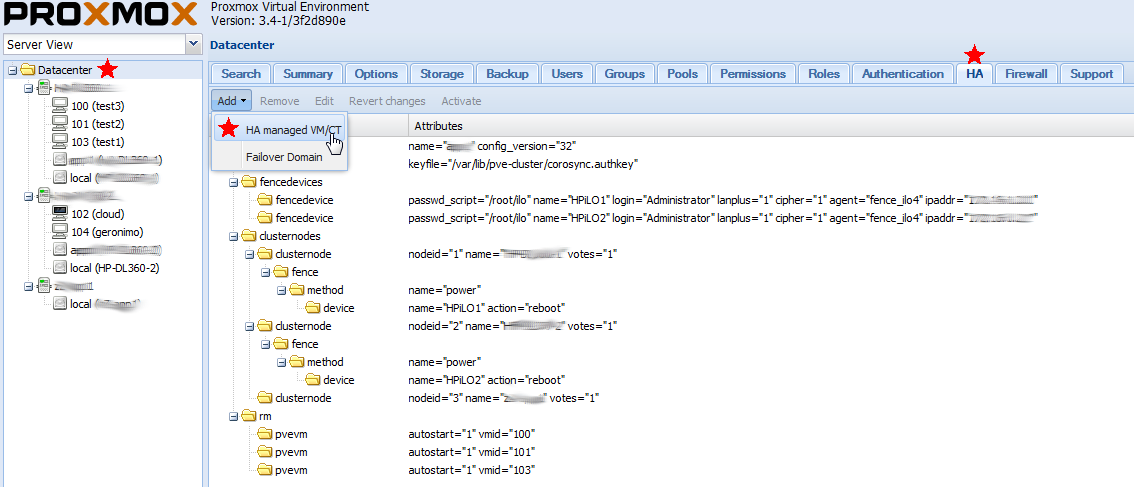
Все, после того, как указанные операции будут выполнены на всех серверах кластера — мы переходим к самой важной и ответственной вещи… правке основного конфига кластера. Нужно действовать очень аккуратно и внимательно. Запомните, после каждой правки конфига — необходимо там же и увеличивать его версию на 1 (параметр config_version=..). Создаем новый временный конфиг:
cp /etc/pve/cluster.conf /etc/pve/cluster.conf.new
Правим его:
nano /etc/pve/cluster.conf.new
Активируем его:
ccs_config_validate -v -f /etc/pve/cluster.conf.new
Вот полностью рабочий конфиг кластера ‘cluster’, который был написан мною вручную: cluster_test1_ilo4
В нем: обозначено 2-а fencing устройства HP iLO, по каждому на сервер (каждый сервер имеет свой HP iLO с отдельным IP адресом), и 3-и ноды (3-я нода, так называемая временная «dummy node», служит для стабилизации работы кластера в случае аварии на одном из серверов.. на ней нет ВМ и fencing-устройств). Действие — перезагрузка. Последний момент, конфиг нужно активировать через веб-GUI. заходим в: Datacenter >>> HA >>> Activate (нажимаем кнопку, она будет активна).
Выглядит это так:

А теперь проверяем работу Fencing-устройства (с любого сервера кластера) и отправляем эту ноду в ребут:
fence_node node1
Все! Больше редактировать конфиги не придется, все дальнейшие действия проводятся через веб-GUI.
6.2) HA
Сервис HA нужно включать для каждой отдельной VM. Внимание: перед включением HA убедитесь, что данная VM выключена.
Так выглядит статус VM без HA:
Добавляем VM в HA:
Активируем:
Новый статус VM с HA:
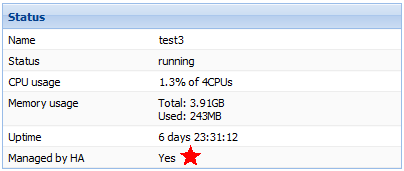
Все! Не забывайте подключать новые VM в HA.
Офф. доки на эту тему: http://pve.proxmox.com/wiki/Fencing
7) Если хранилища нет
Если хранилища нет, то сервера по прежнему могут быть частью кластера — только при этом они будут использовать только свою дисковую подсистему. Их достоинством является то, что такие сервера могут использовать как контейнеры OpenVZ, так и виртуальные машины KVM. Диски виртуальных машин могут быть в нескольких форматах. Особенности форматов дисков:
raw
- наилучшая производительность
- резервирует место под виртуалку полностью (фиксированный диск)
qcow2
- возможность делать snapshot (в т.ч. «живые»)
- резервирует место под виртуалку НЕ полностью (динамический диск)
vmdk
- полная совместимость с VMware
- резервирует место под виртуалку НЕ полностью (динамический диск)
Файлы контейнеров OpenVZ хранятся на самой ноде здесь: /var/lib/vz/private/ID (где ID — айди конейнера в веб-интерфейсе)
8) Работа с OpenVZ
Кратко: контейнеры рекомендуются к использованию, если речь идет о ноде без подключенного к ней хранилища и гостевой linux системе. Колоссальная экономия ресурсов + расширение диска/памяти «на лету».
При работе с Linux-контейнерами OpenVZ, вместо стандартных виртуалок KVM — есть некоторые особенности. Во-первых, файлы контейнеров нельзя разместить в хранилище, подключенном через LVM (только локально). Во-вторых, контейнеры нельзя «клонировать» (но можно создавать из заранее подготовленного шаблона). Если подобный список неудобств вас не смущает и вы готовы использовать контейнеры (за что и будете вознаграждены экономией ресурсов сервера), то можно приступать. Стандартные шаблоны OpenVZ можно закачать прямо через веб-интерфейс Proxmox (во вкладке storage). Но там все шаблоны представлены в архитектуре x86, если нужен х64 — то его можно прямо скачать с сайта OpenVZ: http://openvz.org/Download/templates/precreated и закачать их в той же вкладке веб-интерфейса через функцию Upload. Закачанный шаблон появится в веб-интерфейсе.
Чтобы зайти в контейнер, нужно с ноды выполнить команду (где 109 — ID виртуалки):
vzctl enter 109
Внутри контейнера настраиваем сеть, в зависимости от дистрибутива контейнера. Чтобы заработал вывод через Console в веб-интерфейсе Proxmox (если это нужно), в контейнере необходимо чуть поправить конфиг (в зависимости от дистрибутива контейнера): https://pve.proxmox.com/wiki/OpenVZ_Console
Все, потом настраивайте ОС как вам надо, устанавливаете весь софт (все как на обычной виртуалке). Когда вы полностью настроите контейнер, давайте сделаем из него шаблон… потом уже из этого шаблона можно расплодить целую кучу контейнеров. Прежде чем приступить, нажмите Shutdown в веб-интерфейсе и полностью погасите нужный вам контейнер. Потом, через веб-интерфейс полностью удалите сетевой интерфейс контейнера:
 После этого, зайдите в папку с ID вашего контейнера и выполните команду (где 109 — ID контейнера, а your-template — имя вашего шаблона):
После этого, зайдите в папку с ID вашего контейнера и выполните команду (где 109 — ID контейнера, а your-template — имя вашего шаблона):
cd /var/lib/vz/private/109 tar -cvzpf /var/lib/vz/template/cache/your-temptate.tar.gz .
Точка в конце строки важна, не трогайте ее!
Все, новый шаблон для контейнеров готов к работе. Он появится в веб-интерфейсе Proxmox.
Эксплуатация
Эксплуатация системы реализована полностью через веб-интерфейс, так что никакие доп. требования и доп. ПО не потребуется. Разве что для функции «Console» (просмотра рабочего стола VM) рекомендую установить вам локально Java. Т.к. просмотр рабочего стола возможен в двух режимах: c VNC и без VNC. Режим с VNC — полнофункционален и он работает через Java.
В процессе эксплуатации никаких вопросов возникнуть не должно, все очень логично и интуитивно понятно. При логине в систему, можно даже включить русский язык в интерфейсе. Системой поддерживается живая миграция и живые бекапы, так что виртуальные машины можно свободно перемещать между нодами во включенном состоянии + делать их бекапы. Можно загрузить в локальные хранилища нодов дистрибутивы систем в .iso — что потом делает более комфортным создание новых виртуальных машин.
Пользуйтесь с удовольствием!)